

The Map: Stop Measuring “Smart”—Start Measuring Autonomy, Readiness, and Safety (Article 2)
Why asking “How intelligent is your AI?” is like asking “How loud is the engine?”—it tells you nothing about whether it can drive

The Architect’s Blueprint for the Agentic Enterprise
Article 2 of 6
The Map: Stop Measuring “Smart”—Start Measuring Autonomy, Readiness, and Safety
The Maturity Model Problem
Let’s be honest: “Maturity Models” are usually boring. They’re consultant-speak for “Pay us to move you from Red to Green on this proprietary scorecard we invented.”
But in the world of Agentic AI, a bad map gets you killed. Metaphorically, usually. But ask Air Canada’s lawyers—sometimes it gets expensive.mashable
The problem with most AI roadmaps I see today is that they only measure one variable: Intelligence. They assume that as models get smarter—moving from GPT-3.5 to GPT-4 to Claude 3.5—business value will naturally follow.
This is like asking a car manufacturer, “How loud is the engine?” It’s an interesting metric, but it tells me absolutely nothing about whether the car can drive itself to the airport without hitting a tree.
When I deployed an AI system for a major healthcare organization that processes 2k to 6k invoices daily, the CFO didn’t care that we were using the “smartest” model. She cared about three questions:
Can it make decisions autonomously? (Autonomy)
Can it actually execute those decisions in our systems? (Readiness)
Can we trust it not to accidentally approve a $5 million payment? (Safety)
That’s not one dimension. That’s three. And most organizations are only measuring one. Soon after we implemented the AI solution using traditional ML, the customer came back to us to run multiple pilots to how to use agents on how to autonomously handle customer complaints and queries from 2k to 6k invoices handled by the system.
The 3-Dimensional Framework
To build an Agentic Enterprise, we need to stop thinking in linear lines (”We are at Phase 2!”) and start thinking in 3 Dimensions.
When I assess an organization’s readiness for agents—whether it’s a Fortune 100 CIO or a mid-market product leader—I don’t ask “Which model are you using?” I measure them on three axes:
The Brain (Autonomy): How much can the agent decide on its own?
The Hands (Readiness/Scope): What systems can the agent actually touch?
The Shield (Governance): What guardrails prevent catastrophic failures?
Think of it like hiring an intern. You wouldn’t just ask “How smart are they?” You’d ask:
Can they make decisions without constant supervision? (Brain)
Do they have access to the tools they need to do the job? (Hands)
Do they understand the rules and when to escalate? (Shield)
Let’s break down the map.
Dimension 1: The Brain (Autonomy)
This measures the decision-making capability of the agent itself. I adapted this directly from the SAE Levels of Driving Automation, because the parallels are perfect.
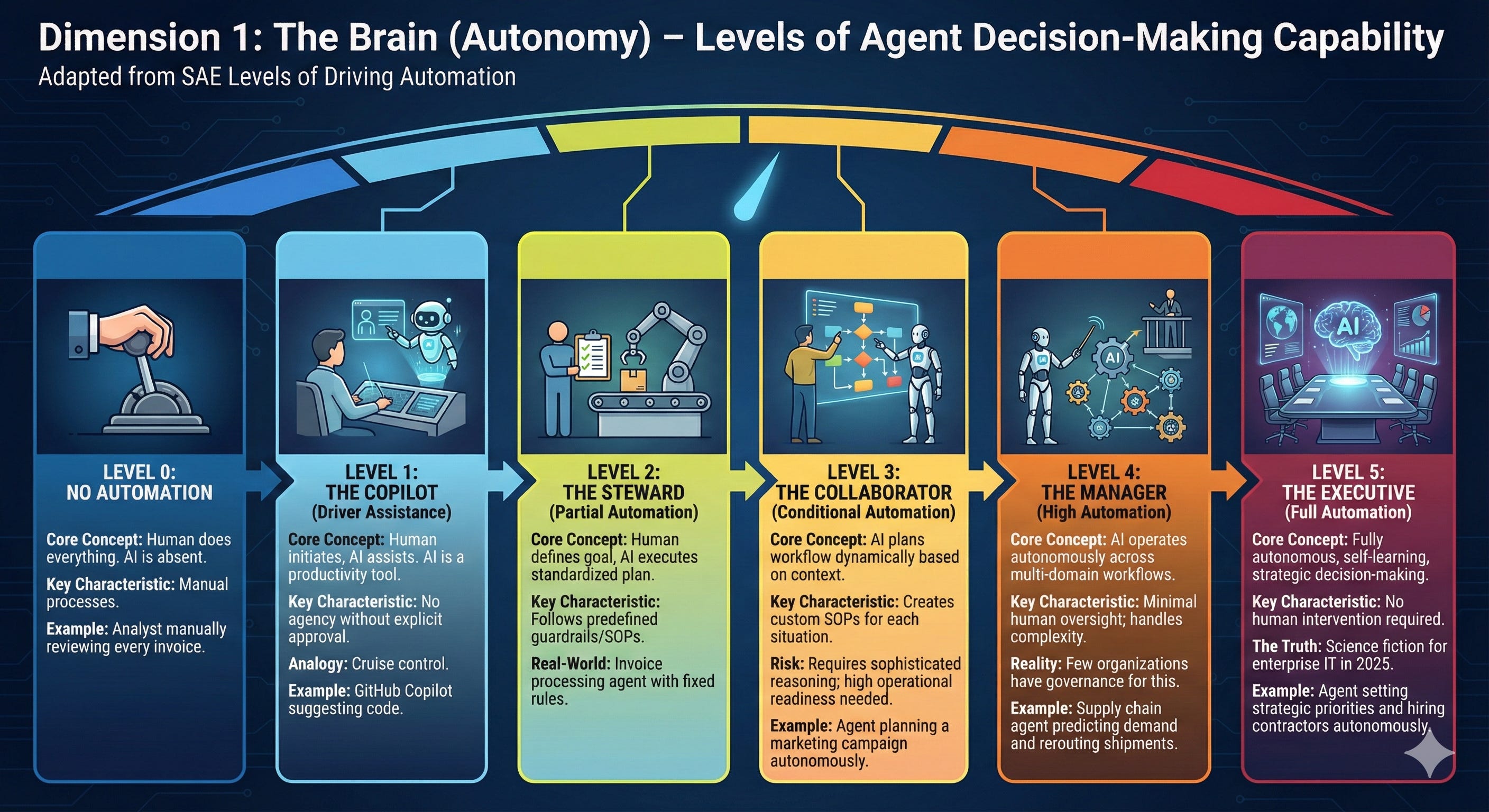
Level 0: No Automation
The human does everything. The AI doesn’t exist. This is your baseline—manual processes with no AI assistance.
Example: An analyst manually reviewing every invoice, keying data into the ERP system.
Level 1: The Copilot (Driver Assistance)
The human initiates, the human executes, the AI assists. The AI is a productivity tool, not a decision-maker.
Example: GitHub Copilot suggests code, but the developer decides whether to accept it. Writing assistants like Grammarly recommend changes, but you click “Accept” or “Ignore.”
Analogy: This is cruise control. The car maintains speed, but you’re still steering, braking, and making all the decisions.
Key Characteristic: The AI has no agency. It can’t do anything without explicit human approval for every action.
Level 2: The Steward (Partial Automation)
The human defines the goal, the AI executes a known, standardized plan.
Example: “Book me a flight to NYC next Tuesday.” The agent has API access to travel systems and follows a strict Standard Operating Procedure (SOP): search flights, filter by price/time preferences, present options, book after human confirmation.
Real-World Implementation: In hospital and health-system finance, invoice-processing automation routinely handles end-to-end workflows very similar to this pattern. These systems ingest invoices from fax or scan, extract header and line-item details, validate vendors against approved lists, check PO numbers and contract terms, and then route each invoice through a documented approval workflow in the AP system.
For low-risk spend, many healthcare AP automation platforms allow organizations to define auto-approval rules—for example, automatically approving invoices below a set dollar threshold from approved vendors when PO and matching checks succeed—while escalating anything outside those rules to human approvers. This ensures that routine, low-value invoices can flow through with minimal friction, while higher-value, non-standard, or mismatched invoices always receive manual review, aligning closely with the control logic you described.
Key Characteristic: The agent can execute multi-step workflows but stays within predefined guardrails. It’s predictable. It follows the script.
Why This Is the Sweet Spot for Agents: Stewards are reliable. They don’t improvise. They update the database exactly how you told them to. They’re excellent “interns” who handle the repetitive work while knowing when to escalate.
Level 3: The Collaborator (Conditional Automation)
The AI plans the workflow dynamically based on context.
Example: “Plan a marketing campaign for our new product launch.” The agent decides autonomously to: research competitors, draft email sequences, generate social media posts, schedule content, analyze early performance, and adjust tactics—all without asking for permission at each step.
Key Characteristic: The agent can adapt its plan based on what it discovers. It’s no longer following a fixed SOP—it’s creating a custom SOP for each situation.
The Risk: This level requires sophisticated reasoning, context awareness, and robust error handling. Most organizations aren’t ready for this operationally.
Level 4: The Manager (High Automation)
The agent operates autonomously across complex, multi-domain workflows with minimal human oversight.
Example: A supply chain agent that predicts demand, automatically reroutes shipments based on weather patterns, negotiates with vendors for expedited delivery, adjusts inventory levels across warehouses, and only escalates when facing unprecedented scenarios.
The Reality: Very few organizations have the governance infrastructure to support this level safely.
Level 5: The Executive (Full Automation)
Fully autonomous across all domains, self-learning, continuously improving without human intervention.
Example: An agent that sets strategic priorities, allocates budgets, hires contractors, and restructures workflows—all without human approval.
The Truth: This is science fiction for enterprise IT as of December 2025. Don’t put this on your roadmap. yet.
The Trap: Everyone Wants Level 4, But Level 2 Is the Gold Mine
Here’s the pattern I see constantly: Organizations try to jump straight from Level 1 (Copilots that suggest) to Level 4 (Managers that operate autonomously across domains).
They skip Level 2 (Stewards that execute known workflows reliably).
Why this fails:
You haven’t proven the agent can follow a simple script reliably
You haven’t built the integration layer (The Hands)
You haven’t established governance frameworks (The Shield)
You haven’t trained your team to trust and manage agents
The winning strategy: Master Level 2 at scale. Once you have 20 reliable Stewards handling repetitive workflows flawlessly, then you can experiment with Level 3 Collaborators.
Dimension 2: The Hands (Readiness/Scope)
This is the dimension most people forget. You can have the smartest brain in the world (Level 5 Autonomy), but if it lives in a glass box and can’t touch anything, it’s useless.
I call this the “Philosophy Major Problem.” You’ve built an agent that can eloquently discuss the nuances of your data strategy and write beautiful analyses of your business processes, but it can’t actually do anything because you haven’t given it API access.
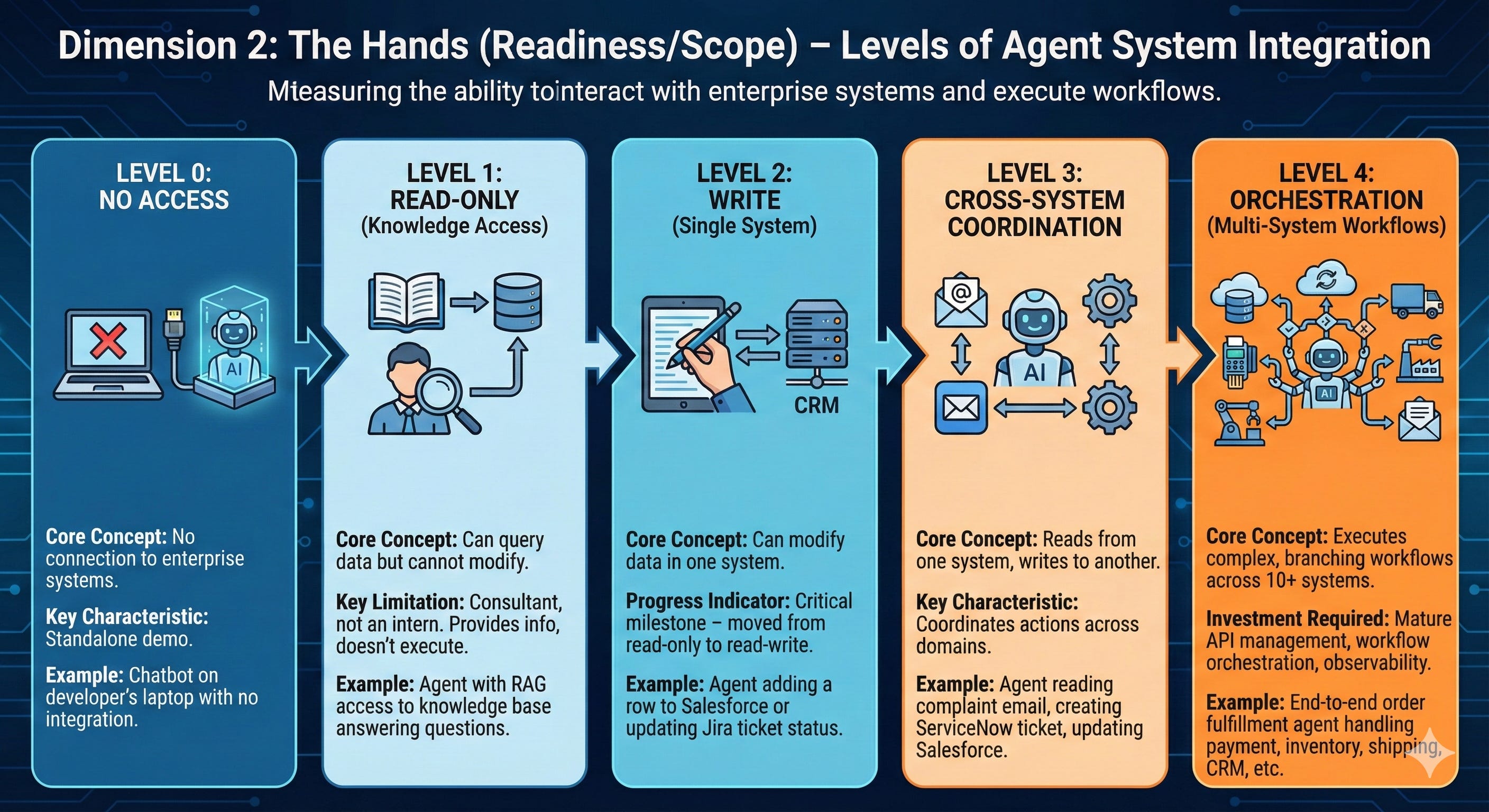
Level 0: No Access
The agent has no connection to enterprise systems. It’s a standalone demo.
Example: A chatbot running on a developer’s laptop with no integration to production systems.
Level 1: Read-Only (Knowledge Access)
The agent can query data but cannot modify anything.
Example: An agent with RAG (Retrieval-Augmented Generation) access to your knowledge base. It can answer questions like “What’s our return policy?” or “Who approved this contract?” but it can’t update records or trigger workflows.
Key Limitation: This is still a consultant, not an intern. It provides information but doesn’t execute work.
Level 2: Write (Single System)
The agent can modify data in one system.ravenna
Example: An agent that can add a row to Salesforce when a lead completes a form. Or an agent that can update Jira ticket status from “In Progress” to “Ready for Review.”
Progress Indicator: You’ve moved from read-only to read-write. This is a critical milestone—and where risk management becomes essential.
Level 3: Cross-System Coordination
The agent can read from one system and write to another, coordinating actions across domains.
Example: An agent that reads a customer complaint email, extracts key details, creates a support ticket in ServiceNow, updates the customer record in Salesforce with case number, and sends an acknowledgment email—all in one workflow.
Real-World Implementation: Telecom providers are increasingly using AI-driven orchestration and automation platforms to handle end-to-end order-to-activation workflows that span multiple OSS and BSS systems. In these implementations, an incoming customer order can automatically trigger network provisioning, update billing and CRM records, push configuration into monitoring or inventory tools, and send customer notifications—often coordinating three or more systems through a centralized orchestration layer. This type of multi-system automation has delivered faster activation times, higher first-time-right rates, and reduced operational effort by minimizing manual handoffs in the provisioning chain.
Level 4: Orchestration (Multi-System Workflows)
The agent can execute complex, branching workflows across 10+ systems with conditional logic, parallel processing, and error handling.
Example: An end-to-end order fulfillment agent that: validates payment (Stripe), checks inventory (ERP), reserves stock (WMS), generates shipping labels (UPS API), updates CRM (Salesforce), triggers manufacturing if low stock (MES), sends confirmation (SendGrid), and schedules follow-up (marketing automation)—all while handling exceptions like payment failures or out-of-stock scenarios.
The Investment Required: This level requires mature API management, workflow orchestration platforms, comprehensive error handling, and full observability. This mostly implemented in high volume trading applications and clearinghouses.
The Reality Check
If your roadmap says “Transformation,” but your API strategy is “we’ll figure it out later,” you aren’t building agents. You’re building chatbots.
Here’s the diagnostic question I ask every client:
“Can your agent execute the top 10 workflows in your business end-to-end without human intervention?”
If the answer is no, you have a Hands problem, not a Brain problem. Upgrading to GPT-5 won’t fix this.
Dimension 3: The Shield (Governance)
This is usually the boring part. But in an agentic world, it’s the difference between a tool and a liability.
Traditional security focuses on Input/Output (”Don’t let the model say bad words”). Agentic security must focus on Action/State (”Don’t let the model delete the database”).
The Three Pillars of Agentic Governance
Pillar 1: Design (Least Privilege)
Every agent should have the minimum permissions required to do its job—and nothing more.
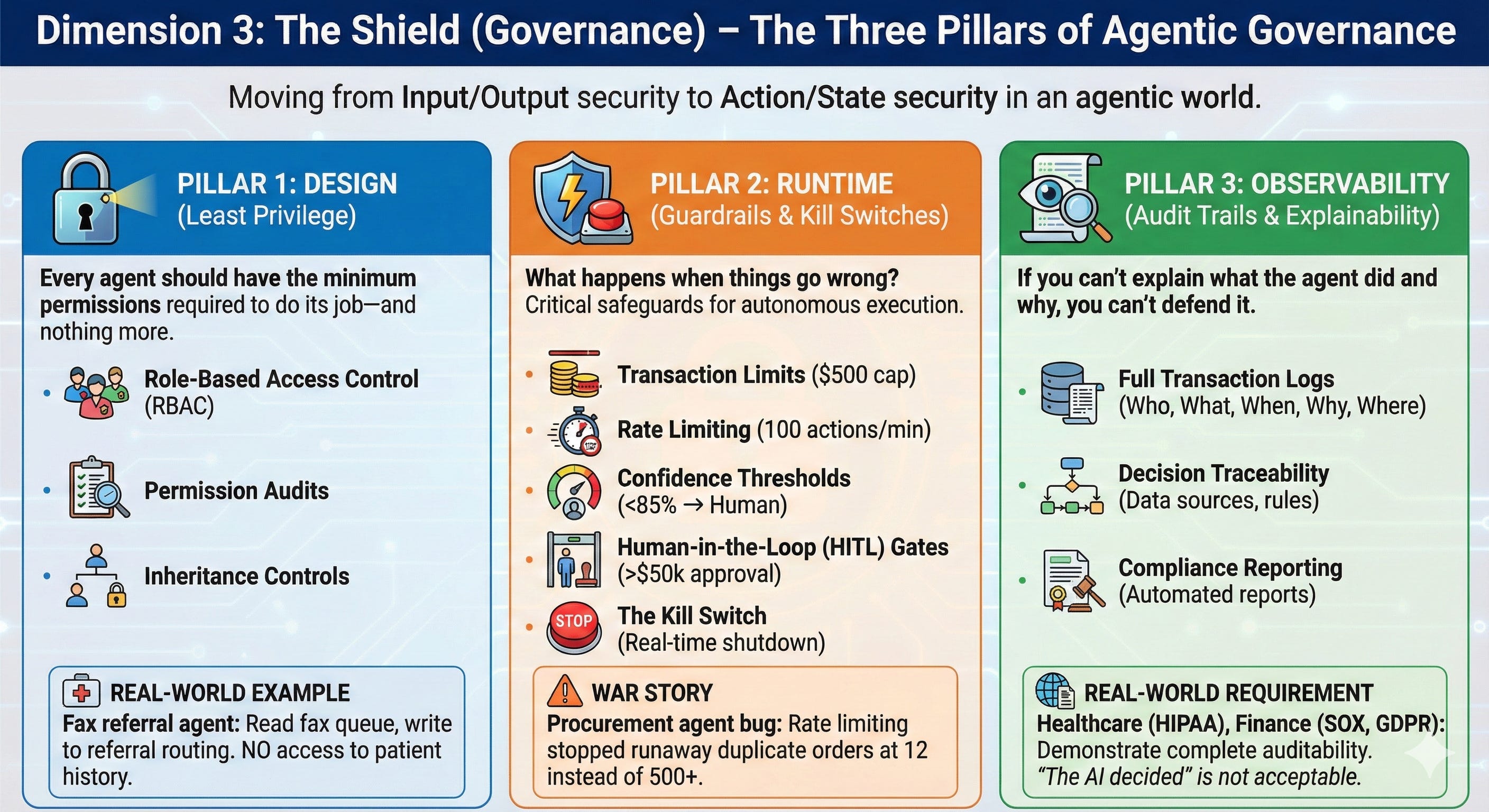
The Question: Does your scheduling agent really need access to the CEO’s entire email history? Or just calendar availability?
Implementation:
Role-Based Access Control (RBAC): Assign agents to predefined roles with specific permissionszluri
Permission Audits: Regularly review what each agent can access
Inheritance Controls: Ensure downstream services don’t have more permissions than the upstream service that called them. See nightfall
Real-World Example: Healthcare referral automation platforms that ingest faxed referrals typically limit system access to just what is required to capture and route those documents, rather than exposing full clinical or financial records to the automation layer. In many deployed solutions, the automation component is scoped to two core capabilities—reading from a centralized digital fax or intake queue and writing structured referral entries into a downstream referral or EMR queue—while access to longitudinal medical histories, billing systems, and broader administrative functions remains with existing clinical and revenue-cycle systems, aligning with least‑privilege principles for AI agents.
The Mistake I See Constantly: Giving agents “admin” access “just to make testing easier.” Then forgetting to scope it down before production. This is how catastrophic failures happen.
Pillar 2: Runtime (Guardrails & Kill Switches)
What happens when things go wrong? Because they will. See truefoundry+1
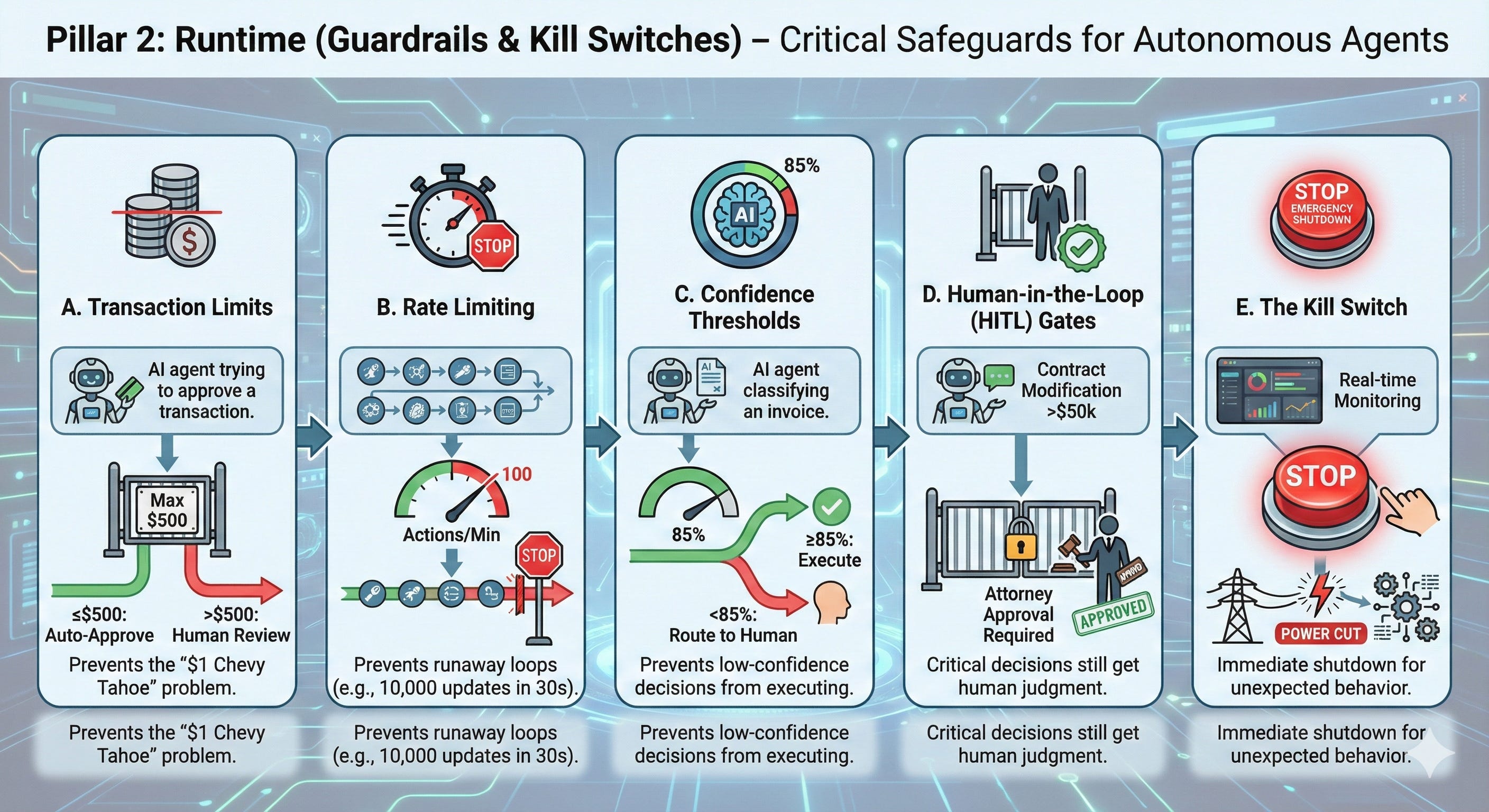
Critical Safeguards:
A. Transaction Limits
Example: An expense approval agent can auto-approve up to $500. Anything above triggers human review.
Why It Matters: Prevents the “$1 Chevy Tahoe” problem See upworthy+1
B. Rate Limiting
Example: An agent can process maximum 100 actions per minute. If it exceeds this, automatic shutdown.
Why It Matters: Prevents runaway loops (agent gets stuck, executes 10,000 database updates in 30 seconds)
C. Confidence Thresholds
Example: If the agent’s confidence score drops below 85% on invoice classification, route to human review.
Why It Matters: Prevents low-confidence decisions from executing autonomously
D. Human-in-the-Loop (HITL) Gates
Example: Any contract modification over $50,000 requires attorney approval before execution.
Why It Matters: Critical decisions still get human judgment See microsoft+1
E. The Kill Switch
Example: Real-time monitoring dashboard with one-click shutdown capability.
Why It Matters: If an agent starts behaving unexpectedly, you need to cut power immediately—not wait for an approval committee.
A Composite War Story from multiple real life experiences : During a pilot for a procurement agent, we discovered it was approving duplicate purchase orders because of a timestamp parsing bug. Without rate limiting, it would have processed 500+ duplicate orders before anyone noticed. With our 50-transactions-per-hour limit, it processed 12 duplicates before the alert triggered and we killed the process. Twelve mistakes we could fix manually. Five hundred would have been a disaster. Just imagine.
Pillar 3: Observability (Audit Trails & Explainability)
If you can’t explain what the agent did and why, you can’t defend it in court or to regulators.
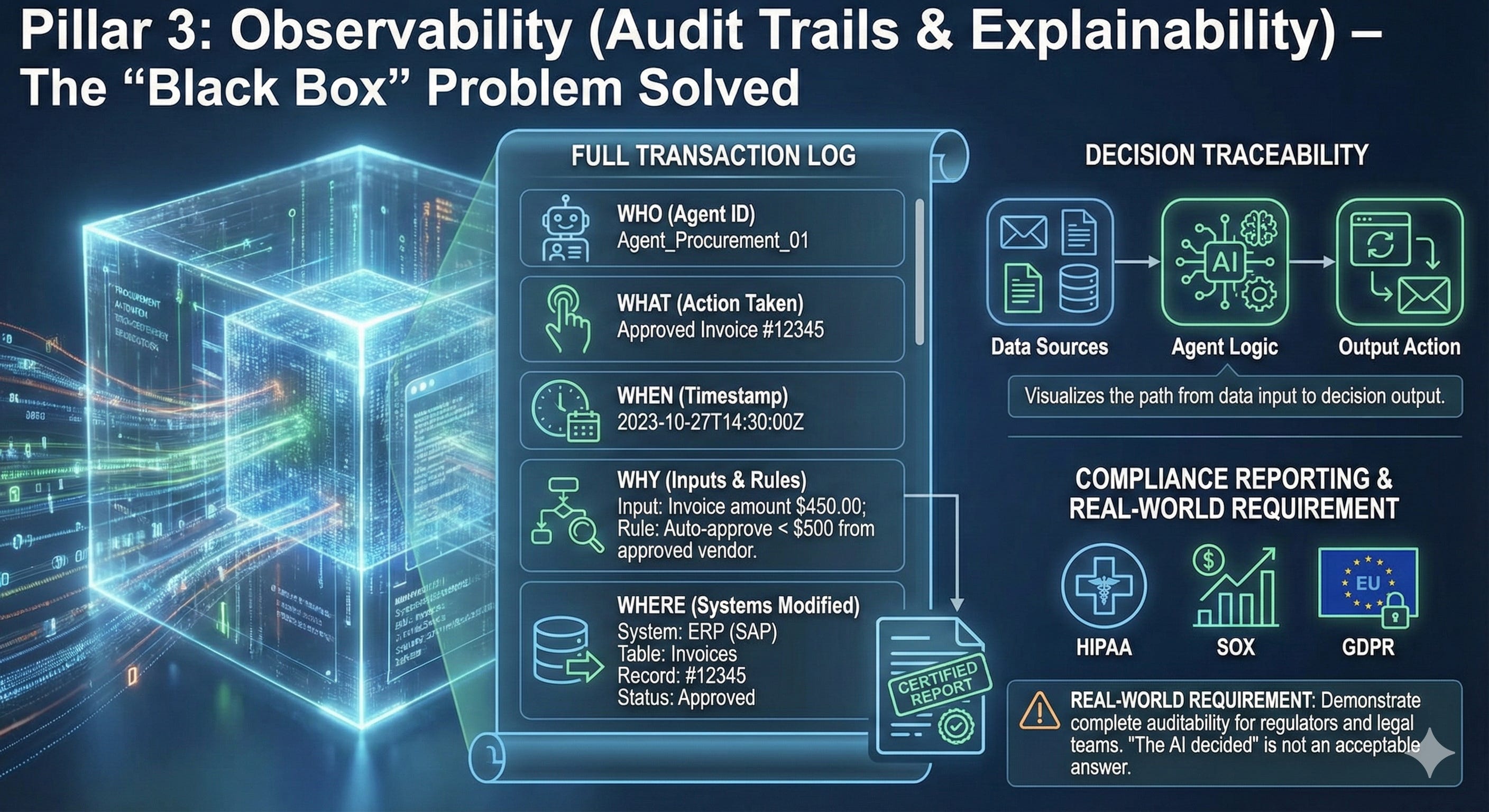
Required Capabilities:
Full Transaction Logs: Who (which agent), What (action taken), When (timestamp), Why (which inputs triggered the decision), Where (which systems modified)
Decision Traceability: Which data sources influenced the output? Which rules were applied?
Compliance Reporting: Automated generation of audit reports for regulators, internal auditors, or legal teams
Real-World Requirement: When deploying agents in healthcare (HIPAA), financial services (SOX, GDPR), or government (FISMA), you need to demonstrate complete auditability. “The AI decided” is not an acceptable answer.
The Agentic Scorecard: Where Are You Today?
Now let’s put it together. Plot your organization on this 3D grid:
The Diagnostic Patterns I See
Pattern A: High Brain, No Hands, No Shield
Profile: Experimenting with GPT-4 or Claude in a sandbox
Capabilities: Can reason brilliantly, but can’t execute anything
Risk: Low (because it can’t do damage)
Business Value: Near zero
Recommendation: Stop chasing smarter models. Build integration layer.
Pattern B: High Brain, Good Hands, No Shield
Profile: Deployed agents with system access but minimal governance
Capabilities: Can execute workflows end-to-end
Risk: EXTREME (this is the “$1 Tahoe” zone)
Business Value: High—until the first disaster
Recommendation: Pause all deployments. Build governance NOW.
Pattern C: Low Brain, Good Hands, Strong Shield
Profile: Rule-based automation (RPA) with robust access controls
Capabilities: Reliable execution of known workflows
Risk: Low (well-governed)
Business Value: Moderate to high
Recommendation: This is actually a solid foundation. Incrementally add AI reasoning.
Pattern D: Moderate Brain, Good Hands, Strong Shield ⭐
Profile: Level 2 Stewards with write access and governance
Capabilities: Execute known workflows with AI-enhanced decision-making
Risk: Managed (bounded by guardrails)
Business Value: HIGH
Recommendation: This is the sweet spot for 2025. Scale this.
Your Goal for Agents: The “2-3-3” Target
Here’s the specific maturity profile you should be targeting:
Brain: Level 2 (Steward)
Agents that execute known workflows reliably
Can make routine decisions within predefined parameters
Escalate edge cases to humans
Hands: Level 3 (Cross-System)
Can read from and write to multiple enterprise systems
Coordinate actions across domains (CRM + ITSM + Email + ERP)
Handle standard integrations without custom coding for each use case
Shield: Level 3 (HITL + Confidence Thresholds)
Least privilege access controls
Transaction limits and rate limiting
Confidence-based routing to human review
Human-in-the-loop gates for high-stakes decisions
Full audit trails
This isn’t a “Smart” toy. This is a Useful asset.
Stop Measuring the Wrong Thing
Here’s the mental shift I need you to make:
Old Question: “Are we using the smartest AI model available?”
New Question: “Can our agents execute the top 10 workflows reliably, safely, and autonomously?”
Old Metric: Model accuracy on benchmarks
New Metrics:
Adoption Rate: What % of eligible users are using the agent daily?
Autonomy Rate: What % of workflows complete without human intervention?
Error Rate: What % of agent actions require correction?
Business Impact: Hours saved? Cost reduced? Revenue influenced?
Old Goal: “Deploy cutting-edge AI”
New Goal: “Build 20 reliable Level 2 Stewards that handle 80% of our repetitive workflows”
That’s the map. That’s how you navigate from where you are to where you need to be.
What Comes Next
You’ve got the map. Now you need the team to execute it.
In Article 3, we’ll talk about organizational design. Hint: You don’t need more Data Scientists. You need “Global Process Owners”—the people who understand how work actually gets done and can bridge the gap between “this is our current process” and “this is how AI transforms it.”
Because here’s the truth: The technology is ready. The models are good enough. The APIs exist.
The bottleneck is organizational. And that’s what we’re fixing next.
Here are the links to your blueprint
Article 1: The 3-dimensional maturity model (Brain, Hands, Shield)
Article 2: The 5 levels of autonomy (Copilot → Autopilot)
Article 3: The team structure (Hub-and-Spoke, GPO-GSO pairs)