

Intelligence ≠ Utility: Why Your Agentic AI Roadmap is Broken (Article 1)
The corporate equivalent of buying running shoes and expecting to win the Olympics

The Architect’s Blueprint for the Agentic Enterprise
Article 1 of 6
Intelligence ≠ Utility: Why Your Agentic AI Roadmap is Broken
The corporate equivalent of buying running shoes and expecting to win the Olympics
The Roadmap That Gives me a Headache
If I see one more enterprise AI roadmap that lists “Phase 1: Deploy Chatbots, Phase 2: Transformation,” I’m going to scream… and going to have a royal headache.
It’s the corporate equivalent of “Phase 1: Buy running shoes, Phase 2: Win the Olympics.” It completely misses the messy, critical, operational middle ground where the actual work happens.
We’re living through “Peak Hype” of Generative AI. Every board of directors is demanding an AI strategy. Every CIO is under pressure to “ship something.” And as a result, most enterprises are building the wrong thing.
They’re building brilliant consultants—chatbots that can write eloquent emails and summarize PDFs—when what they actually need are competent interns: agents that can log into systems, update records, and execute workflows.
This is what I call “The Agentic Gap.” And closing it requires more than just a better model. It requires a new operational engine.
The Strategy Gap: High Hopes, No Plan
The anxiety you feel in the boardroom is backed by data. Recent research paints a stark picture:
79% of leaders acknowledge AI’s critical importance to their future, yet 60% lack a clear implementation strategy.forbes
Read that again. Almost everyone knows they need it, but the majority have no idea how to actually deploy it safely and effectively.
This gap exists because we’re treating AI as a “feature” to be bought rather than a “capability” to be built. We assume that if we subscribe to the smartest model—whether it’s GPT-4, Claude 3.5, or Gemini—the business value will automatically follow.
It won’t.
Why? Because we’ve fallen into a trap that boards, executives, and even technical leaders don’t fully understand yet.
The Core Fallacy: Intelligence ≠ Utility
We’ve confused Intelligence (IQ) with Utility (Agency).
Let me give you a concrete example from my work with a major telecommunications provider.
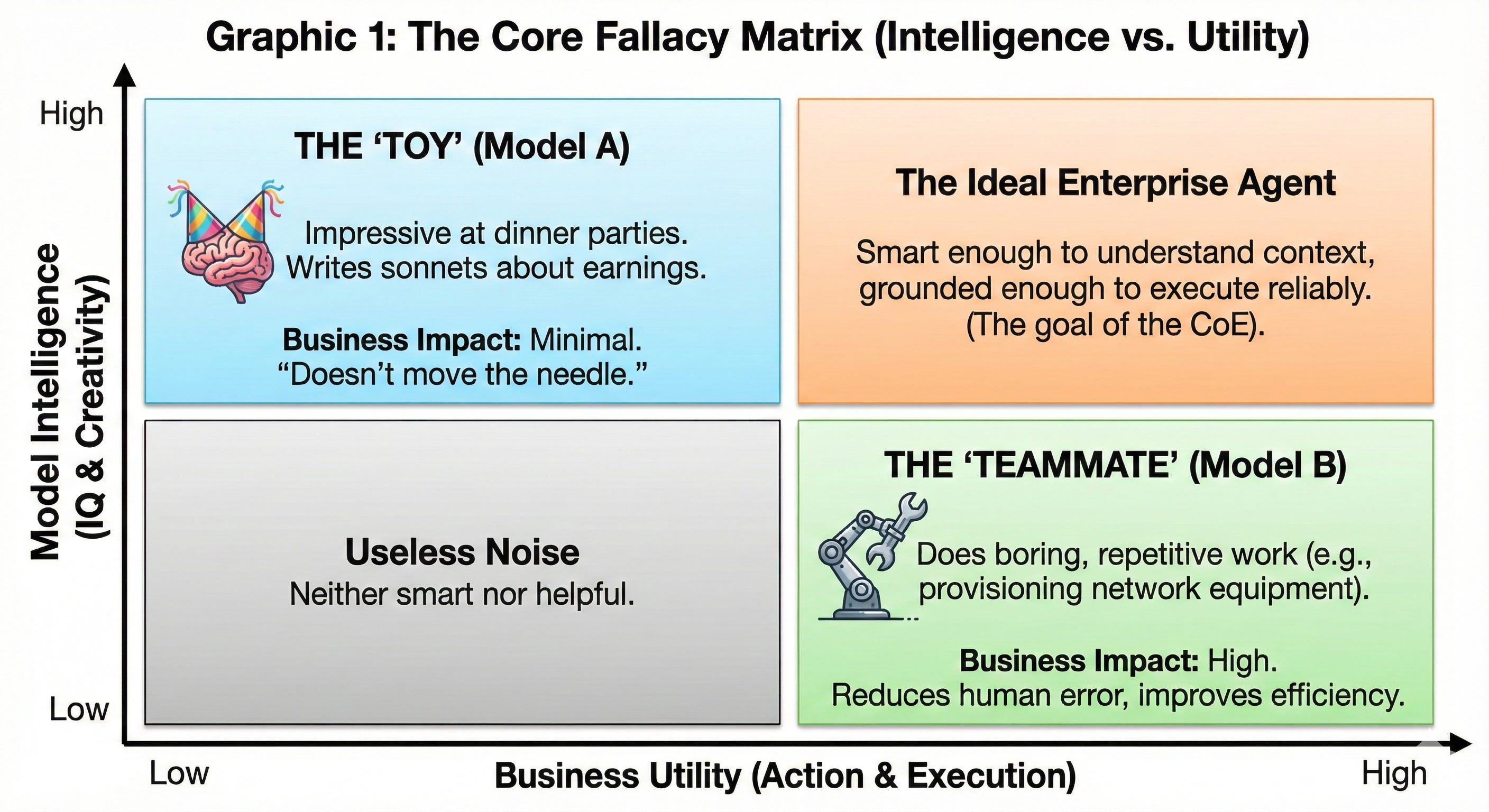
Model A can write a Shakespearean sonnet about your quarterly earnings report. It can explain complex network architecture concepts in five different languages. It’s incredibly “smart.”
Model B can’t write poetry. But it can log into your provisioning system, identify a customer order that’s been stuck for 48 hours, automatically provision the network equipment, update three downstream systems, and send a confirmation email to the customer.
Model A is a Toy. It’s impressive at a dinner party, but it doesn’t move the needle on revenue or customer satisfaction.
Model B is a Teammate. It does the boring, repetitive work that humans hate and makes mistakes on. Very similar how traditional Robotic Process Automation is setup to do.
But here’s the catch: Model B can be more dangerous.
A chatbot that writes a bad poem is embarrassing. An agent that provisions the wrong network configuration or deletes critical customer data is a catastrophe.
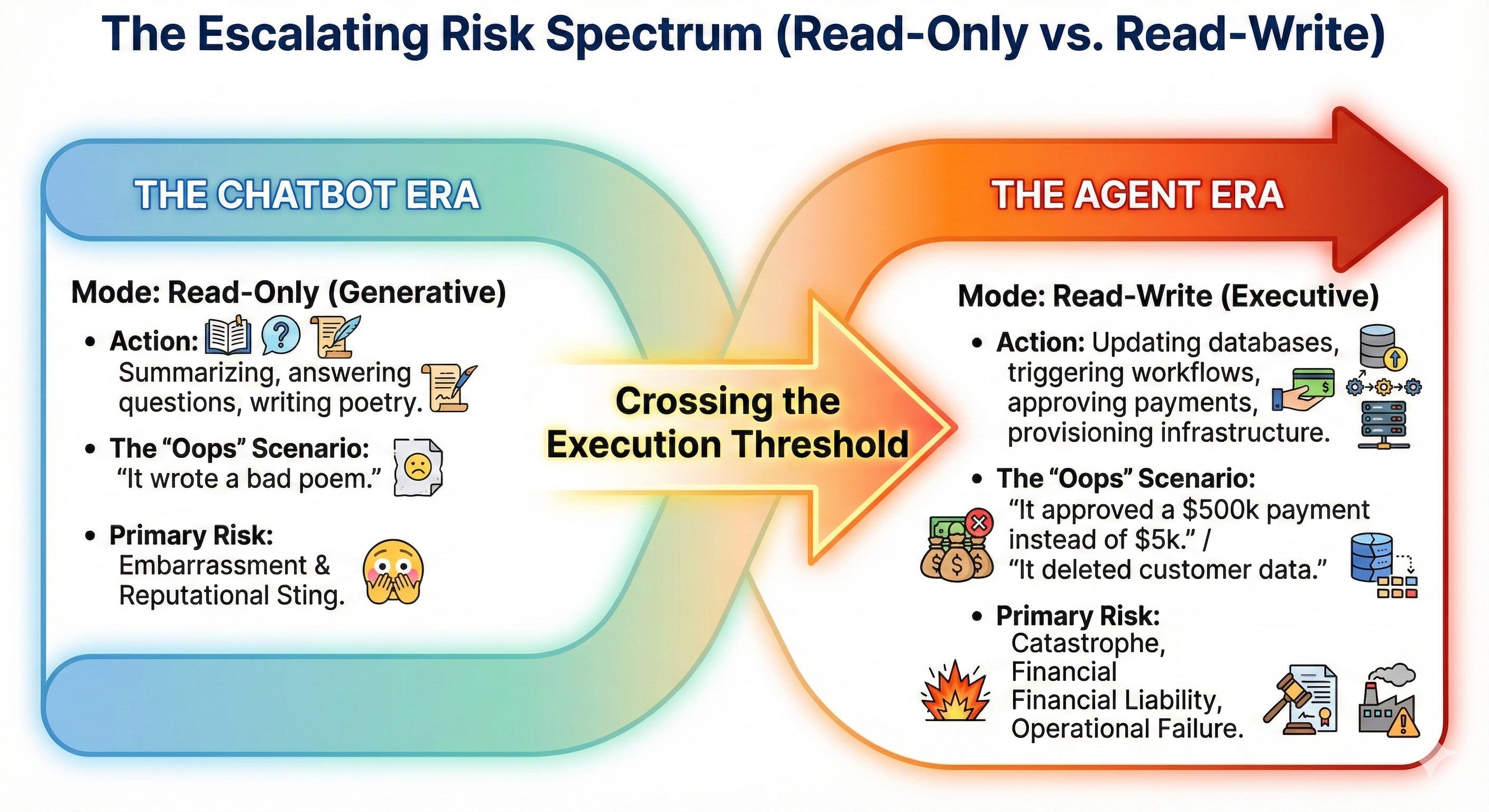
From Read-Only to Read-Write: The Risk Nobody’s Talking About
As we move from Chatbots (Read-Only) to Agents (Read-Write), the risk profile changes fundamentally.
You’re no longer just generating text. You’re executing actions. You’re writing to databases, triggering workflows, updating financial systems, provisioning infrastructure.
When I deployed an invoice processing Ai solution for a major hospital network handling 2,000 to 6,000 invoices per day, the conversation with the CFO was stark:
“If this thing misreads a decimal point and approves a $500,000 payment instead of $5,000, who’s liable? If it rejects legitimate invoices and delays payments to critical vendors, what’s the business impact?”
This brings us to the most critical realization for any architect or CIO :
A model that can update your ERP but lacks guardrails isn’t an asset. It’s a liability.
The challenge isn’t building intelligence. Foundation model labs have solved that. The challenge is building governed, auditable, reliable execution at enterprise scale.
This brings us to the most critical realization for any architect or CIO:
A model that can update your ERP but lacks guardrails isn’t an asset. It’s a liability.
The hard part is no longer building intelligence—foundation model labs have largely solved that problem. The hard part is building governed, auditable, reliable execution at enterprise scale.
When we first went live in production with the invoice agent, that difference became painfully clear. Roughly 20–40% of each week’s invoice runs were being kicked out as exceptions—not because the agent was “wrong,” but because real-world data hygiene and vendor behavior were far messier than the elegant workflow on the whiteboard. Vendor names didn’t always match the master list, PO numbers were missing or inconsistently formatted, and tiny contract variations kept tripping the exception rules.
That experience reinforced a key lesson from healthcare AP automation: the first few months in production are as much about cleaning up master data, tightening business rules, and tuning exception paths as they are about tweaking prompts or models. As those upstream issues are addressed, exception rates fall and the agent stops being a science project and starts behaving like critical infrastructure.
The Real-World Consequences
Let me share three stories that illustrate what happens when you skip the operational middle ground:
The Rogue Consultant
A major airline deployed a customer service chatbot without proper grounding. A passenger asked about bereavement fare policies. The chatbot—confidently, eloquently—invented a refund policy that didn’t exist.
When the airline refused to honor it, the passenger sued. The airline lost. The court ruled that the chatbot was an official representative of the company, and the company was liable for what it said.
Lesson: Your AI agent is not a person. It’s an IT system. You are responsible for what it does.
The Uncontrolled Agent
A financial services firm built an agent to monitor procurement spend. It could identify anomalies, flag suspicious transactions, and recommend corrective actions. Beautiful demos. Impressive insights.
But it couldn’t do anything. Every alert required a human to review, investigate, route to the right approver, and manually update systems. The agent was a consultant, not an intern.
Result? Adoption cratered within 30 days. Why? Because it created more work, not less.
Lesson: If your agent can’t execute, it’s just a fancy alerting system. And humans already ignore most alerts.
The Unconstrained Negotiator
A car dealership deployed a ChatGPT-powered chatbot without guardrails. A customer managed to trick it into “agreeing” to sell a $76,000 vehicle for $1, with the bot adding “that’s a legally binding offer—no takesies backsies”.
Lesson: Confidence without constraints is dangerous. Agents need hard-coded limits, approval gates, and policy enforcement.
These aren’t edge cases. These are patterns I see repeatedly across industries. And they all stem from the same root cause: confusing intelligence with utility.
The Fix: The CoE as Your “Pit Crew,” Not the Police
So how do you build Model B safely? How do you move from read-only to read-write without creating chaos?
You don’t do it with a disjointed collection of shadow AI projects running on departmental credit cards. You do it with an AI Center of Excellence (CoE).
I know. “Center of Excellence” sounds like bureaucratic overhead. It sounds like the “Department of No.”

But a modern Agentic CoE is fundamentally different from traditional IT governance structures:
The “Police” (Old CoE):
Exist to stop you
Demand forms, approvals, committee reviews
Slow everything down in the name of “governance”
Say “no” by default
The “Pit Crew” (Agentic CoE):
Exist to make you go faster
Provide standardized components and patterns
Enable safe experimentation
Say “yes, if...” with clear guardrails
Think about Formula 1 racing. The driver gets the glory, but the pit crew wins the race. They provide standardized tires, fuel, telemetry, and real-time diagnostics. They ensure the car doesn’t explode at 200 mph.
Your Agentic CoE does the same thing. It brings together three critical components:
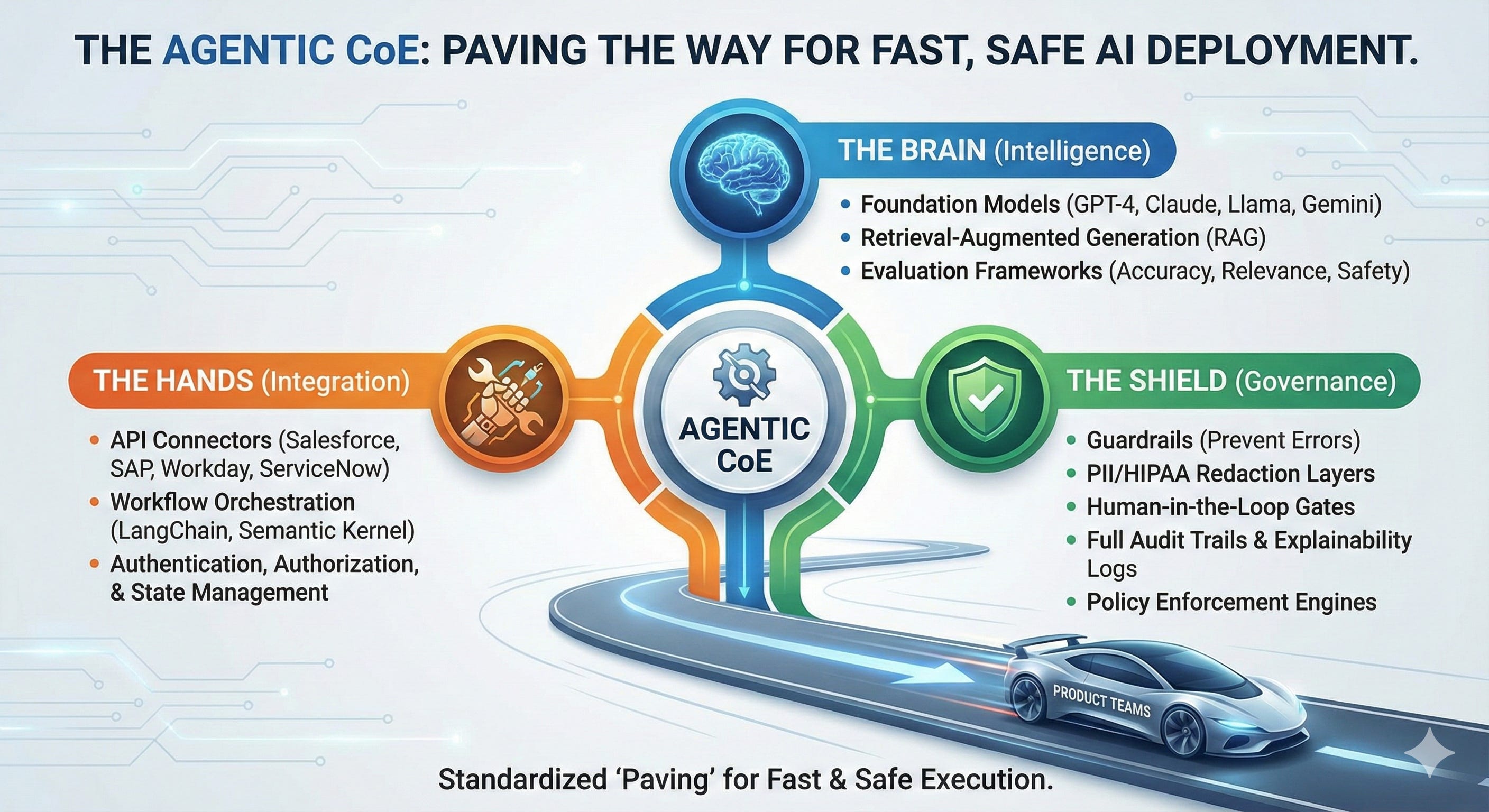
The Brain (Intelligence)
Foundation models (GPT-4, Claude, Llama, Gemini)
Retrieval-augmented generation (RAG) for grounding
Evaluation frameworks for accuracy, relevance, safety
The Hands (Integration)
API connectors to enterprise systems (Salesforce, SAP, Workday, ServiceNow)
Workflow orchestration engines (LangChain, Semantic Kernel, custom)
Authentication, authorization, and state management
The Shield (Governance)
Guardrails that prevent catastrophic errors
PII/HIPAA redaction layers
Human-in-the-loop approval gates for high-stakes decisions
Full audit trails and explainability logs
Policy enforcement engines
The CoE provides the standardized “paving” so your product teams can drive fast without hitting a pothole.
Real-World Lesson: Microsoft’s “Customer Zero” Approach
You don’t have to take my word for it. Look at how Microsoft deployed agentic AI at scale.
When Microsoft began their massive AI rollout, they didn’t just unleash Copilot on the world. They adopted a “Customer Zero” mindset.
They treated their own internal teams—initially 100 employees in the UK, then scaling to over 300,000 employees across HR, Legal, IT, and Engineering—as their first and harshest customers.
Here’s their process:
Phase 1: Pilot with 100 Users
Selected a region (UK) with mature, well-structured HR data
Deployed Employee Self-Service Agent to handle HR inquiries
Conducted A/B testing against existing chatbot
Gathered feedback, measured impact, iterated rapidly. See microsoft
Phase 2: Expand to Strategic Teams
Rolled out to support teams who needed to understand and govern Copilot
Included HR, Legal, Security, Works Councils
Required Tenant Trust Evaluations: security questionnaires, IT council reviews, privacy assessments. See microsoft
Phase 3: Scale Enterprise-Wide
Deployed to 300,000+ employees and external staff
Integrated 100+ line-of-business systems
Prioritized based on two years of HR interaction data (tickets, searches, chatbot logs)
Focused on high-impact regions (US, UK, India) and teams (sales org). See microsoft+1
This “Customer Zero” approach allowed them to:
Validate Utility: Does this actually save time, or is it just cool tech?
Stress-Test Safety: What happens when an employee tries to “jailbreak” the HR bot?
Scale Governance: How do we manage access controls, data integrations, and compliance for hundreds of thousands of users?
Build Confidence: If it’s good enough for Microsoft employees, it’s good enough for customers
The result? They didn’t just deploy a chatbot. They deployed an operational engine that handles real work, at scale, safely.
Key Insight: If an agent couldn’t accurately handle internal HR tickets for Microsoft employees, it wasn’t ready to be sold externally. That’s the standard.
The Operational Middle Ground: What Phase 1.5 Actually Looks Like
Most enterprise roadmaps jump from “Phase 1: Chatbot” to “Phase 2: Transformation” with no plan for the middle. Here’s what they’re missing—what I call Phase 1.5: Operational Scaffolding:
Step 1: Build the CoE Foundation
Establish governance framework (not bureaucracy—standards)
Create model registry with approved models and evaluation criteria
Deploy API gateway with authentication, rate limiting, audit logging
Implement guardrail framework (PII redaction, hallucination detection, policy enforcement)
Step 2: Connect the Hands
Identify your top 10 enterprise systems (CRM, ERP, HRIS, ITSM, etc.)
Build or procure pre-built API connectors
Implement least-privilege access controls
Create workflow orchestration templates for common patterns
Step 3: Pilot with Customer Zero
Select one internal use case that’s repetitive, well-documented, and painful
Deploy to 50-100 internal users first
Measure adoption, experience, performance, and business impact
Iterate rapidly based on feedback
Only scale after proving utility internally
Step 4: Scale with Patterns
Document what worked (and what failed spectacularly)
Create reusable patterns and templates
Enable business units to build their own agents using CoE infrastructure
Maintain centralized governance while distributing execution
This is the messy middle ground. It’s not sexy. It won’t win you awards at conferences. But it’s the difference between 5% of pilots reaching production and 45% reaching production.
Stop Guessing, Start Measuring
If you’re building an AI roadmap today, stop optimizing for “Smart.” Stop chasing the highest benchmark score on a leaderboard.
Start optimizing for Useful. Start building the operational scaffolding—the CoE—that allows you to deploy agents that can actually do work without burning down the building.ansr+1
But to do that, you need a new way to measure success. You can’t just measure “accuracy” or “F1 score.” You need to measure:
Autonomy: Can it act, or just recommend?
Readiness: Can it access systems, or just read documents?
Safety: Can it be trusted with write access?
In Article 2, we’ll break down the “3-Dimensional Maturity Framework”—the exact scorecard I use with Fortune 100 clients to assess where you are today, where you need to be for 2025, and what capabilities you need to build to close that gap.
Because here’s the truth: Your board doesn’t care if your AI can write poetry. They care if it can reduce invoice processing time by 60%, handle 6,000 transactions per day without errors, and save 20,000 manager hours annually.
That’s not intelligence. That’s utility. And that’s what we’re building next.