

4. Reflection - Teaching Your AI to Double-Check Its Work and Improve Its Own Quality
Reflection is the AI That Double-Checks Its Own Work. Move from "first draft" quality to "final polish" reliability.

4. Reflection — Agentic Design Pattern Series
Reflection is a pattern where an AI agent critically evaluates its own generated output, identifies its flaws, and then uses that critique to create a refined, higher-quality final version.
The AI That Double-Checks Its Own Work. Move from "first draft" quality to "final polish" reliability.
This pattern is the single most powerful technique for elevating the quality of your agent's output. Instead of just accepting the first thing the LLM generates, you build a process of self-correction. For a business, this is the difference between an AI that produces passable but error-prone code and one that generates code that is tested, debugged, and production-ready. It's how you build trust in your AI's results and reduce the need for human oversight.
📺 Diagram and Video
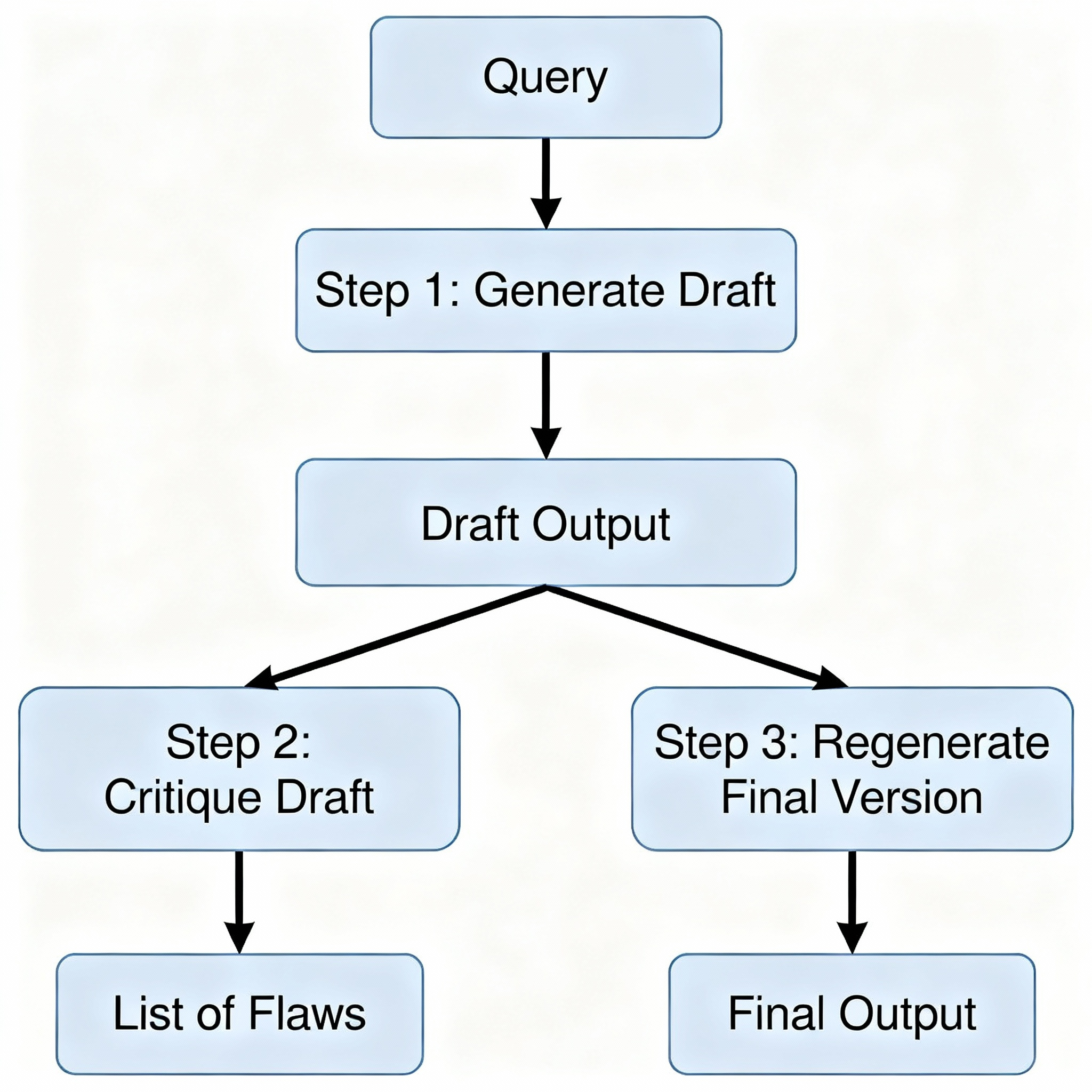
A visual of the self-correction loop:
Query -> [Step 1: Generate Draft] -> Draft Output -> [Step 2: Critique Draft] -> List of Flaws -> [Step 3: Regenerate Final Version using Draft + Flaws] -> Final Output
LangGraph: Building Cyclical and Stateful Agents
YouTube: Build a Multi-Agent System with LangGraph by LangChain
Introduces building multi-agent, cyclical, and stateful workflows with LangGraph—showing how to implement reflection, feedback loops, and sophisticated state handling for advanced AI agent deployments.
🚩 What Is Reflection?
"The first draft is just you telling yourself the story. The real work begins when you start to critique, question, and refine that story into something true. We must teach our agents to do the same."
Reflection is a multi-step process that mimics the human creative cycle of drafting and revising. The agent first generates an initial response to a query. Then, in a separate step, it is prompted to act as a critic, reviewing its own work against a specific set of criteria (e.g., factual accuracy, tone, code quality). Finally, it uses the original draft and its own critique to generate a new, superior version.
🏗 Use Cases
Scenario: A legal tech company uses an AI agent to generate summaries of complex legal contracts. A single-prompt approach might miss subtle clauses or misinterpret specific legal jargon, which is unacceptable.
Applying the Pattern:
Incoming Query: "Summarize this 50-page commercial lease agreement, highlighting all tenant responsibilities and liabilities."
Step 1 (Generate Draft): The agent produces an initial summary of the document.
Step 2 (Reflection/Critique): The draft is fed into a "Reflector" prompt. This prompt instructs the LLM to act as a senior paralegal and check the summary specifically for:
Missed tenant obligations.
Ambiguous phrasing.
Incorrectly defined legal terms.
The reflector produces a bulleted list of necessary corrections.
Step 3 (Regenerate): A final prompt is given all the information: the original document, the first draft, and the reflector's critique. It is instructed to "rewrite the draft to incorporate this feedback."
Outcome: The final summary is far more accurate and reliable, having been vetted through a targeted, critical review process.
General Use: This pattern is invaluable for any task that demands high accuracy, coherence, or adherence to complex constraints.
Content Creation: Writing a detailed report, then reflecting on its clarity, tone, and factual accuracy.
Code Generation: Writing a function, then reflecting by running tests, checking for bugs, or ensuring it meets style guidelines.
Problem Solving: Answering a multi-step reasoning question, then double-checking the logic and calculations.
💻 Sample Code / Pseudocode
This Python pseudocode demonstrates the three-step reflection process.
def call_llm(prompt):
"""Simulates an LLM API call."""
print(f"--- Calling LLM for: {prompt.splitlines()[0]}...")
# This is a highly simplified simulation for clarity.
if "write a python function" in prompt.lower():
# Initial draft has a bug (uses '>' instead of '>=')
return "def is_adult(age):\\n return age > 18"
elif "review the following python code" in prompt.lower():
return "- The function fails for age 18. It should use '>='."
elif "rewrite the code" in prompt.lower():
return "def is_adult(age):\\n return age >= 18"
return "Error: Unknown prompt."
def generate_code_with_reflection(task_description):
"""
Generates code using a draft, critique, and refinement loop.
"""
# Step 1: Generate the initial draft
draft_prompt = f"Please write a Python function for the following task: {task_description}"
initial_draft = call_llm(draft_prompt)
print(f"--- Initial Draft: ---\n{initial_draft}\n")
# Step 2: Generate a critique of the draft
reflection_prompt = f"""
Review the following Python code for bugs and edge cases.
Provide a bulleted list of specific improvements.
Code:
{initial_draft}
"""
critique = call_llm(reflection_prompt)
print(f"--- Critique: ---\n{critique}\n")
# Step 3: Regenerate the final version using the critique
final_prompt = f"""
Rewrite the code based on the provided critique.
Original Code:
{initial_draft}
Critique:
{critique}
Final, Corrected Code:
"""
final_version = call_llm(final_prompt)
print(f"--- Final Version: ---\n{final_version}")
return final_version
# --- Execute the workflow ---
generate_code_with_reflection("Check if a person is an adult (18 or older).")
🟢 Pros
Dramatically Increases Quality: The primary benefit. Catches errors a single pass would miss.
Reduces Hallucinations: Self-correction helps ground the model and improve factual accuracy.
Enhanced Reliability: The final output is more trustworthy because it has undergone a review process.
🔴 Cons
Increased Latency & Cost: This pattern at least triples the number of LLM calls, making it slower and more expensive.
Inefficient Loops: A poor reflection prompt can lead to trivial changes or getting stuck in a refinement loop without meaningful progress.
Risk of Over-Correction: The agent might "correct" things that were already right or make creative content too bland.
🛑 Anti-Patterns (Mistakes to Avoid)
Generic Reflection Prompt: Using a vague critique prompt like "Is this good?" is useless. The prompt must be specific and persona-driven (e.g., "You are a senior editor. Check for passive voice and run-on sentences.").
Reflecting on Simple Tasks: Using this pattern for simple, low-stakes tasks (like rephrasing a sentence) is overkill and a waste of resources.
Ignoring the First Draft: The final prompt must include the original draft along with the critique. Forgetting it forces the LLM to regenerate from scratch, losing the context of the original attempt.
🛠 Best Practices
Use a Stronger LLM for Reflection: Use a cheaper, faster model for the initial draft and a more powerful, intelligent model (e.g., GPT-4, Gemini 1.5 Pro) for the critical reflection step.
Targeted Critiques: Create different "reflector" personas for different tasks. A
code_reviewershould check for bugs, while acopy_editorshould check for grammar and style.Limit the Number of Loops: For automated reflection cycles, set a hard limit of 1-2 refinement loops to prevent infinite cycles and control costs.
🧪 Sample Test Plan
Unit Tests: Test the reflector prompt. Provide it with a pre-written draft containing known flaws and assert that its critique correctly identifies them.
End-to-End (Integration) Tests: Test the full, three-step workflow. Provide a query and assert that the final version is measurably better than the first draft. This can be checked with an LLM Judge.
Robustness Tests: Feed the workflow tasks where the initial draft is already perfect. The reflection step should ideally produce an output like "No major issues found," and the final version should be nearly identical to the draft.
🤖 LLM as Judge/Evaluator
Recommendation: This pattern is a perfect candidate for evaluation using an LLM Judge. The goal is to prove that the final version is consistently better than the draft.
How to Apply: Set up a "head-to-head" evaluation. Give the judge LLM the initial query, the first draft, and the final version. Ask it: "Which response is better, A or B? Explain your reasoning." Run this across your test dataset. Your goal should be a >90% preference for the final version.
🗂 Cheatsheet
Variant: Generate-and-Test
When to Use: Primarily for code generation. The "reflection" step involves actually running the generated code against unit tests.
Key Tip: If the tests fail, the error output serves as the "critique" for the next generation step.
Variant: Multi-Persona Debate
When to Use: For complex, subjective topics. Generate an initial argument, then have two other agents (e.g., a "pro" and "con" persona) critique it in parallel.
Key Tip: The final aggregation step involves synthesizing the arguments and critiques into a balanced overview.
Variant: Fact-Checking Loop
When to Use: For fact-based content generation. The reflection step involves using a web search or database tool to verify every claim made in the first draft.
Key Tip: The critique is a list of "unverified" or "incorrect" claims that need to be corrected.
Relevant Content
Self-Refine: Iterative Refinement with Self-Feedback (arXiv:2303.17651): https://arxiv.org/abs/2303.17651 (The key academic paper that formally introduces and evaluates this pattern).
LangGraph Documentation: https://langchain-ai.github.io/langgraph/ (The go-to open-source library for building agentic loops and state machines required for reflection).
📅 Coming Soon
Stay tuned for our next article in the series: Design Pattern: Tool Use — Giving Your AI an Arsenal of Tools to Interact With the World.