

3. Parallelization - Supercharging Your AI's Speed by Running Tasks in Parallel.
Parallelization is the Multi-Lane Highway for AI. Stop waiting in line; get faster answers by working in parallel.

Parallelization — Agentic Design Pattern Series
Parallelization is the pattern of executing multiple independent tasks simultaneously and then aggregating their results, dramatically reducing the total time it takes for an AI agent to complete complex requests.
The Multi-Lane Highway for AI. Stop waiting in line; get faster answers by working in parallel.
This pattern is the key to unlocking speed and efficiency in your AI applications. Instead of a slow, step-by-step process, you can run multiple queries, data lookups, or LLM calls all at once. For a business, this means a financial analysis tool can fetch data for five different companies simultaneously, not one after another. The result is a user experience that feels instantaneous instead of sluggish, transforming a five-minute wait into a 30-second interaction.
📺 Diagram and Videos
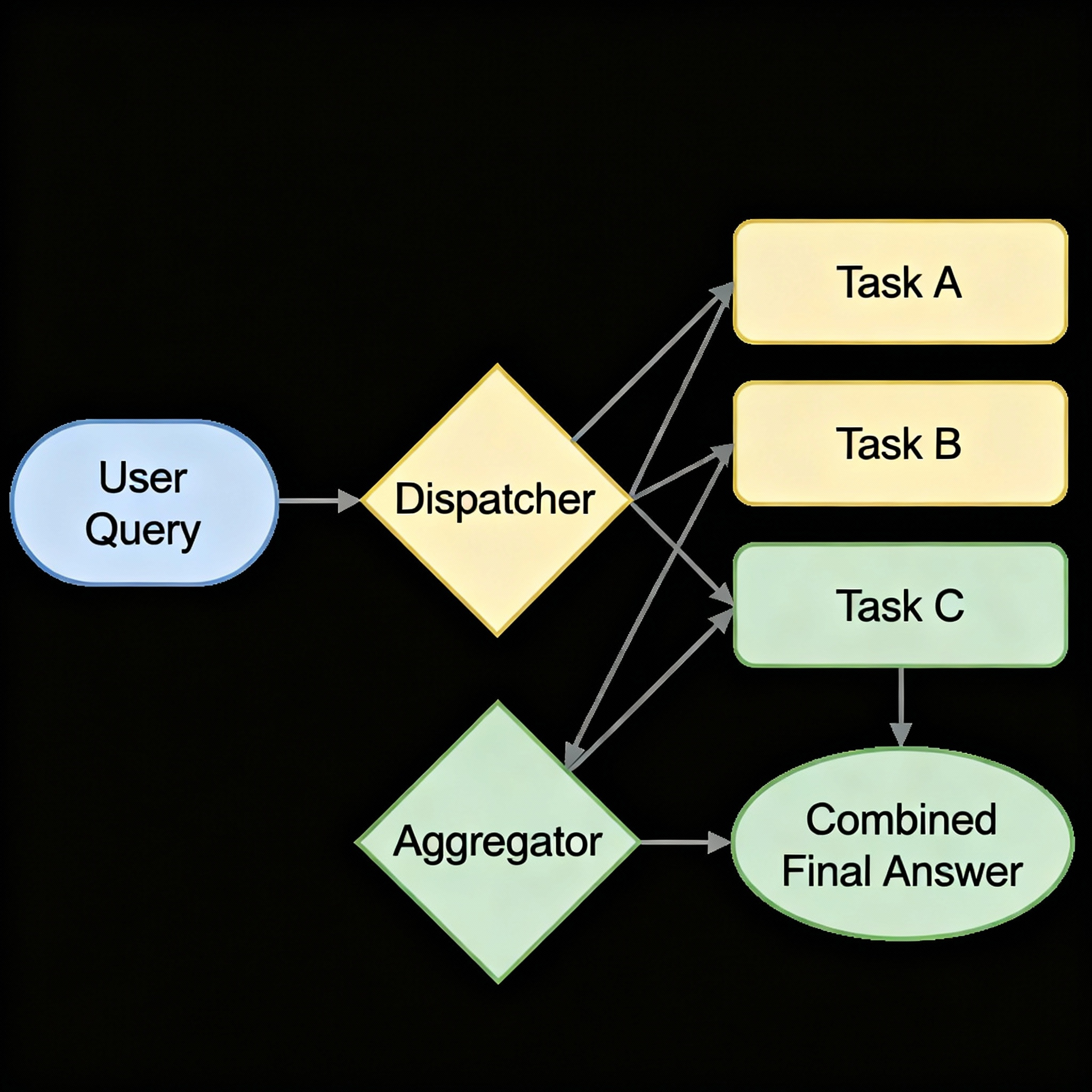
A visual of the concurrent flow:
Langraph Intro on Parallelism
🚩 What Is Parallelization?
"The time it takes to complete a hundred independent tasks isn't a hundred times one task. It's the time it takes to complete the single longest task. That is the magic of working in parallel."
Parallelization involves breaking a larger problem into smaller, independent sub-tasks and executing them all at the same time. Once all concurrent tasks are finished, a final aggregation step combines their individual outputs into a single, cohesive result. This is designed to drastically cut down on the total latency, or wait time, for the end-user.
🏗 Use Cases
Scenario: A market research firm needs to create a report comparing three competitor products. A sequential approach would involve researching Product A, then Product B, then Product C, which is slow and inefficient.
Applying the Pattern:
Incoming Query: "Create a competitive analysis of Product A, Product B, and Product C, focusing on features, pricing, and customer reviews."
Dispatch Step: The agent identifies that the research for each product is independent. It creates three parallel tasks:
Task A: A chain to find features, pricing, and reviews for Product A.
Task B: An identical chain for Product B.
Task C: An identical chain for Product C.
Concurrent Execution: All three tasks are initiated simultaneously. The total wait time is now determined only by the longest of the three tasks, not their sum.
Aggregation Step: Once all three research tasks are complete, their outputs are fed into a final LLM prompt that synthesizes the information into a structured, comparative report.
Outcome: The report is generated in roughly one-third of the time it would have taken using a sequential prompt-chaining approach.
General Use: This pattern is perfect for any task that can be broken into sub-problems that do not depend on each other.
Comparative Analysis: Answering "Compare the pros and cons of X, Y, and Z."
Gathering Diverse Data: Responding to "What are the latest developments in AI, biotech, and fusion energy?"
Generating Multiple Perspectives: "Generate three different marketing slogans for our new product."
💻 Sample Code / Pseudocode
This Python pseudocode uses asyncio to run multiple simulated LLM calls concurrently.
import asyncio
import time
async def call_llm_async(prompt):
"""Simulates an asynchronous LLM API call with a delay."""
print(f"--- Starting task for prompt: {prompt[:30]}...")
await asyncio.sleep(2) # Represents the network latency of an API call
result = f"This is the result for '{prompt[:30]}...'"
print(f"--- Finished task for prompt: {prompt[:30]}...")
return result
async def run_parallel_workflow(topics):
"""
Runs an LLM call for each topic in parallel and aggregates the results.
"""
start_time = time.time()
# Step 1: Create a list of concurrent tasks
tasks = [call_llm_async(f"Summarize the topic of {topic}") for topic in topics]
# Step 2: Run all tasks concurrently and wait for them to complete
individual_results = await asyncio.gather(*tasks)
print("\n--- All parallel tasks completed. --- \n")
# Step 3: Aggregate the results
aggregation_prompt = "Combine the following summaries into one report:\n"
for i, result in enumerate(individual_results):
aggregation_prompt += f"{i+1}. {result}\n"
# In a real app, you'd call the LLM again here. We'll just format it.
final_report = aggregation_prompt
print(f"--- Final Aggregated Report: ---\n{final_report}")
end_time = time.time()
print(f"Total time taken: {end_time - start_time:.2f} seconds.")
# Note: The total time will be ~2 seconds (the time of the longest task),
# not ~6 seconds (the sum of all tasks).
# --- Execute the workflow ---
asyncio.run(run_parallel_workflow(["AI ethics", "Quantum mechanics", "Roman history"]))
🟢 Pros
Drastic Speed Improvement: Massively reduces latency. The total time is dictated by the slowest task, not the sum of all tasks.
Increased Throughput: More work gets done in the same amount of time.
Resilience: The failure of one parallel task doesn't necessarily stop the others from succeeding.
🔴 Cons
Resource Intensive: Can be more expensive as it requires making multiple API calls at once, potentially hitting rate limits.
Synchronization Complexity: The results from all branches must be collected and meaningfully combined in an aggregation step.
Limited Applicability: Only works for tasks that have no dependencies on each other.
🛑 Anti-Patterns (Mistakes to Avoid)
Parallelizing Dependent Tasks: The most common mistake. Trying to run tasks in parallel when one task's input depends on another's output will fail. This scenario requires Prompt Chaining.
Forgetting Aggregation: Running tasks in parallel is only half the job. You must have a well-defined final step to synthesize the separate results into a useful answer.
Ignoring Rate Limits: Kicking off hundreds of parallel API calls can get your API key throttled or banned. Implement proper error handling and backoff strategies.
🛠 Best Practices
Use for I/O-Bound Tasks: Parallelization is most effective for tasks that involve waiting, like API calls, database queries, or reading files (I/O-bound).
Combine with Routing: Use a Router to decide if a query can be parallelized. If yes, dispatch to a parallel workflow; if not, use a sequential chain.
Graceful Failure: Design your aggregation step to handle cases where one or more of the parallel tasks might fail or time out.
🧪 Sample Test Plan
Unit Tests: Test your aggregation logic. Provide it with a mock set of results (including potential error/null values) and assert that it combines them correctly.
End-to-End (Integration) Tests: Run the full parallel workflow and assert that the final, aggregated output is correctly formed and contains elements from all the parallel branches.
Robustness Tests: Test what happens when one of the parallel API calls fails. Does the entire workflow crash, or does the aggregator handle it gracefully?
Performance Tests: The primary goal of this pattern is speed. Measure the latency of the parallel workflow vs. a sequential version of the same workflow. The speedup should be significant.
🤖 LLM as Judge/Evaluator
Recommendation: Use an LLM judge to evaluate the quality of the synthesis in your aggregation step.
How to Apply: Give the judge LLM the outputs from the individual parallel branches and the final aggregated report. Ask it to score from 1-10 how well the report combines the information without losing key details. This helps you refine your final aggregation prompt.
Cheatsheet
Variant: Scatter-Gather
When to Use: The classic use case. A query is "scattered" to multiple sources, and the results are "gathered."
Key Tip: Ensure all scattered tasks are working towards a common, cohesive goal.
Variant: Comparative Generation
When to Use: When you want to generate multiple different versions of something (e.g., email drafts, slogans).
Key Tip: No aggregation step may be needed; you can simply present all the generated options to the user.
Variant: Multi-Source RAG
When to Use: In Retrieval Augmented Generation (RAG), when you need to fetch context from multiple documents or databases at once.
Key Tip: The retrieval step is parallelized, and the combined context is then fed into a single LLM call for synthesis.
Relevant Content
LangChain Expression Language (LCEL): https://python.langchain.com/docs/expression_language/ (The
RunnableParallelclass is the canonical implementation).MapReduce Paper (Google Research): https://research.google/pubs/pub62/ (The foundational academic concept from distributed computing that established the principles of parallel processing and aggregation).
📅 Coming Soon
Stay tuned for our next article in the series: Design Pattern: Reflection — Teaching Your AI to Double-Check Its Work and Improve Its Own Quality.